Markup consists basically of codes, or tags (also called tokens), that are added to text to change the look or meaning of the tagged text. The tagged text for a document is usually called the source code, or just code, for that document. Most word processors, desktop publishing systems, and even simple text editors that can produce formatted text use some sort of markup language. For example, this book was written using Microsoft Word, which supports the markup language RTF (Rich Text Format).
Markup is commonly used to change the look of text by adding formatting, such as bold or italic fonts, text indents, font sizes, and font weights. Markup tags typically work by turning these attributes on when they are needed and off when they are not. Let's look at an example.
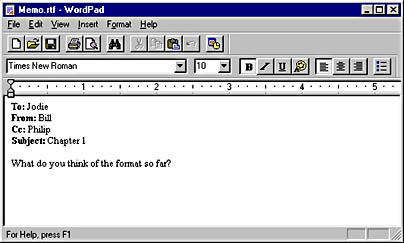
As I mentioned, Word supports the RTF markup language. The WordPad applet that comes with Microsoft Windows also supports RTF. Following is a short memo document formatted in RTF using WordPad:
This text looks like any other text you might see when using a word processor or desktop publishing program or even while viewing a Web page. But as already stated, this text has been formatted with RTF and saved as an RTF file. Here is how the tagged text, or code, for this document looks:
{\rtf1\ansi\ansicpg1252\deff0\deftab720{\fonttbl
{\f0\fswiss MS Sans Serif;}
{\f1\froman\fcharset2 Symbol;}
{\f2\froman Times New Roman;}}
{\colortbl\red0\green0\blue0;}
\deflang1033\pard\plain\f2\fs20\b To: \plain\f2\fs20 Jodie
\par \plain\f2\fs20\b From: \plain\f2\fs20 Bill
\par \plain\f2\fs20\b Cc: \plain\f2\fs20 Philip
\par \plain\f2\fs20\b Subject: \plain\f2\fs20 Chapter 1
\par
\par What do you think of the format so far?
\par }
|
The tagged text looks much different than the displayed text, doesn't it! This code tells the application that processes it (called a processor) just about everything the application needs to know about the text in the document. The markup tags throughout the document tell the application everything, from the markup language used (see the \rtf1 tag at the beginning) to the color of the text (\colortb1\red0\green0\blue0) to where each new line begins (\par). One visible feature of the displayed text in the screen shot above is that some text is bold and other text is not. This is indicated in the code as well. In the code, notice the \b tag that appears just before the word To: on the sixth line. That tag "turns on" the bold attribute for that line of text. Just after the word To:, you'll see the \plain tag. This tag effectively "turns off" bold and "turns on" plain, which is really the same as no formatting at all.
As you can see, after you know a little about what each of the tags means, the RTF code is actually quite readable. However, this is not always true with other markup languages. If you try to look at a document saved in Word Document format, for example, it will not look like much. Here is our memo document saved in Word Document format and viewed as plain text.
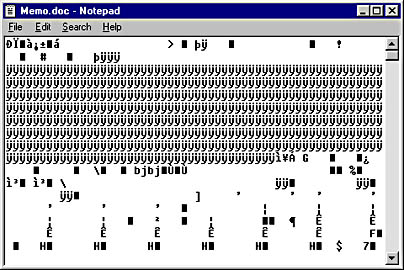
Word adds some extra "stuff" to the RTF markup tags and saves the entire document as a binary file, which isn't readable as text. Word Document format is also closed, which means that it is not publicly available. The implication is that vendors do not have access to the rules for the markup language and therefore cannot create their own processors for the language. The specification for an open language, on the other hand, is publicly available—allowing any vendor to create a processor for it. Some vendors are looking for ways to package HTML documents, which are in open formats, into compressed or binary formats to make their code more secure. In fact, Microsoft Internet Explorer 5 provides a way to package all the elements on an HTML page into a single binary file, allowing an author to deliver a single file instead of having to deliver separate HTML files, graphic files, and so on for every page. This "packaging" does not mean that the HTML language itself would be closed; it means that the code for some documents would not be viewable, as it is today.
You might be wondering how the RTF code was retrieved from the WordPad display in the first screen graphic. Here's a simple explanation: I created the document in WordPad and saved it. I then opened the document in Notepad, a plain-text application. Since Notepad cannot interpret the RTF tags, it simply displays everything in the document without applying any formatting to the text, so human eyes can easily read all the code in the document.
This illustrates an important notion about markup. For markup to work properly, it requires that a processor read the markup codes, interpret how they affect the text, and display the results. WordPad acts as the processor for RTF, but WordPad cannot process any other markup language, such as HTML. So if you were to open an HTML document in WordPad, you would see the plain text and markup tags, not the formatted text.
If you look closely at the RTF markup code in the example in the section "A Look at RTF Markup" you will notice that it is impossible for you to derive the structure of the document simply from the code shown. Nothing within the markup tells you whether rules exist to govern how the document should be put together. The author of the document can place words and formatting anywhere in the document and in any order. While this kind of freedom might seem desirable, it can actually create a lot of problems. For one thing, it makes it difficult for human readers to interpret the markup code of a complex document. While you might be able to decipher a specific section of the markup, you would not be able to determine why it is located there or whether it is related to other markup. This loose structure also makes it almost impossible for someone else to author a document of exactly the same type. For example, if someone wanted to make another memo similar to ours, they would have to make an exact copy of all the code we used and then replace only those parts that needed to be changed in the new memo. While that might be possible with small documents, it would be extremely difficult with long and complex documents. Yet another problem is that this particular document is not necessarily portable to other platforms or devices. Since no rules exist for how this document is structured, it would be difficult for someone else to create a processor that will interpret the document accurately. And the document would certainly not be extensible beyond the markup already coded into it. In other words, without the ability to set rules for a document, it is impossible to create other types of reusable document structures from the original document.
As you might have guessed, the problems described above are not new ones. And of the efforts to fix the problems, some are more complex than others. One of the most popular solutions is HTML. Let's look at this same document using the HTML markup language.
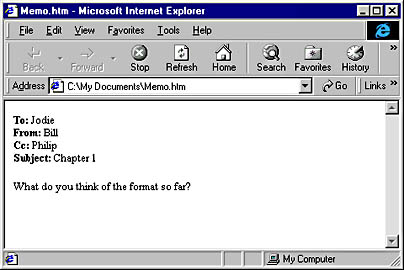
As you can see, the HTML document looks pretty much the same as the RTF document, even though the markup is completely different. Let's look at the HTML markup code:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 FINAL//EN">
<HTML>
<HEAD>
<TITLE>Memo</TITLE>
</HEAD>
<BODY>
<FONT FACE="Times New Roman" SIZE="2">
<P>
<B>To: </B>
Jodie<BR>
<B>From: </B>
Bill<BR>
<B>Cc: </B>
Philip<BR>
<B>Subject: </B>
Chapter 1
</P>
<P>
What do you think of the format so far?
</P>
</FONT>
</BODY>
</HTML>
|
If you closely examine this document's markup, you can see that an implicit structure has been applied to the document. Notice that the <HTML> tag appears at the beginning and a similar tag, </HTML>, appears at the end. Everything else within the document is contained between these tags. Also notice the Head element, the Title element, and the Body element. Each of these pieces of code has a specific place and purpose in the document. Now look at some of the formatting tags. The markup includes bold formatting, as does the RTF document, but notice that two bold tags are used—one to turn bold on (<B>) and another to turn it off (</B>).
HTML's structure is not accidental. HTML documents are supposed to conform to a specific set of rules that identify exactly how a document should be put together. These rules tell the processor which elements are available in HTML markup. They identify which elements can and cannot be contained "inside" other elements, and they identify what types of external files are allowed in a document. They even set the rules for linking to other documents or files, a process called hyperlinking. All of the rules are included in the Document Type Definition (DTD). You might have noticed the line at the beginning of the HTML code that included the letters DTD. This line is called a document type declaration, and it tells the processor which DTD to use. DTDs will be discussed in Chapter 4, but if you are not familiar with them, all you need to know at this point is that each DTD works as a blueprint that defines a document structure.
Although each HTML document is supposed to conform to a DTD, in real-world applications, HTML processors (most often Web browsers) do not check a document against the DTD, nor do they even read the DTD. Because of this, most browsers let HTML authors break the rules a bit. For example, in the Memo.htm file shown previously, you could break the rules by putting the Title element outside the Head element or the Body element outside the HTML element. (You really shouldn't write code in this way, but the point is that you could do it and most browsers would still be able to read it.) As you come to understand XML, however, you will see that this casual approach to markup rules does not work when writing XML code.
NOTE
An element in many markup languages is simply a pair of opening and closing tags. For example, <TITLE> and </TITLE> are tags, but if you put them together, as in <TITLE></TITLE>, you have created a Title element. Most elements also contain some content between the opening and closing tags, as does the example above: <TITLE>Memo</TITLE>. However, not all markup languages require an opening tag and a closing tag to make up a valid element. In some cases, a single tag (usually the opening tag) is all that is needed.