Eine effiziente Möglichkeit zur Implementation von Serpent bietet der sogenannte bitslice-Modus. Die Idee der Implementation soll hier kurz vorgestellt werden, da das Design des Algorithmus explizit darauf zugeschnitten ist. Die Idee des bitslice-Modus ist es, eine S-Box nicht als eine Funktion von und auf 4-Bit Folgen, sondern als vier boolesche Funktionen zu betrachten.
Klassische Modellierung einer S-Box:
Alternative Modellierung der S-Box:
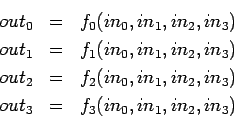
Die 32-fach parallele Anwendung einer S-Box entspricht also entweder der Berechnung der entsprechenden 4-Bit Funktion für 32 Eingaben, oder aber einer Permutation der Eingabe-Bits, der einmaligen Berechnung der vier booleschen Funktionen auf 32-Bit Wörtern, sowie einer Permutation der Ausgabe-Bits (invers zur Permutation der Eingabe). Die bitweise Verknüpfung von 32-Bit Wörtern kann im allgemeinen wesentlich schneller durchgeführt werden, als 32 Zugriffe auf die Tabelle der S-Box.
Da bei Serpent der bitslice-Modus bereits während der Entwicklungsphase als Standardimplementation vorgesehen war,
entschieden sich die Entwickler die Bits nicht beim bitslice-Modus zu permutieren, sondern nur in dem anderen Modus.
Diese Permutationen sind in der Algorithmusbeschreibung in Form von ![]() (initial permutation) und
(initial permutation) und ![]() (final permutation) präsent. Somit wird durch Entfernen aller Anwendungen von
(final permutation) präsent. Somit wird durch Entfernen aller Anwendungen von ![]() und
und ![]() aus den obigen Formeln,
die Darstellung des Algorithmus in den bitslice-Modus übertragen.
aus den obigen Formeln,
die Darstellung des Algorithmus in den bitslice-Modus übertragen.