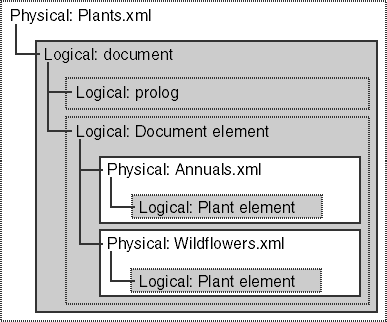
One of XML's best qualities is its ability to provide structure to a document. Every XML document includes both a logical structure and a physical structure. The logical structure is like a template that tells you what elements to include in a document and in what order. The physical structure contains the actual data used in a document. This data might include text stored in your computer's memory, an image file stored on the World Wide Web, and so on. To get an idea of how an XML document is structured, examine the document model shown in Figure 3-1.
Figure 3-1. An XML document has a logical structure and a physical structure.
If you are familiar with HTML, you are probably familiar with the concept of logical structure. Logical structure refers to the organization of the different parts of a document. Put another way, logical structure indicates how a document is built, as opposed to what a document contains. The logical structure of an HTML document, for example, is indicated by the elements that make it up, as shown in the following code:
<HTML>
<HEAD>
<TITLE>Title content goes here</TITLE>
Other Head content goes here
</HEAD>
<BODY>
Body content goes here
</BODY>
</HTML>
|
This code indicates that the Head, Title, and Body elements are all contained within the Html element; that the Title element is located inside the Head element; and so on. The HTML 3.2 Document Type Definition (DTD), found at http://www.w3.org/TR/REC-html32.html#dtd, provides the complete rules for how an HTML document should be built.
NOTE
An XML document is made up of declarations, elements, processing instructions, and comments. Some components are optional and some are required. This section examines the basic declarations and elements of an XML document as a sample document is built. The other components will be discussed in the next chapter.
The first structural element in an XML document is an optional prolog. The prolog consists of two basic components, also optional: the XML declaration and the document type declaration.
The XML Declaration The XML declaration identifies the version of the XML specification to which the document conforms. Although the XML declaration is an optional element, you should always include one in your XML document. The sample document begins with a basic XML declaration:
<?xml version="1.0"?> |
NOTE
The above line of code must use lowercase letters.
An XML declaration can also contain an encoding declaration and a stand-alone document declaration. The encoding declaration identifies the character encoding scheme, such as UTF-8 or EUC-JP. Different encoding schemes map to different character formats or languages. For example, UTF-8, the default scheme, includes representations for most of the characters in the English language. XML parsers are required to support certain Unicode schemes, enabling support for most human languages.
The stand-alone document declaration identifies whether any markup declarations exist that are external to the document (more on this later). The stand-alone document declaration can have the value yes or no.
NOTE
For more information on the specifics of the encoding declaration or the stand-alone document declaration, see sections 2.8, 2.9, and 4.3.3 in the XML 1.0 specification included on the companion CD.
The Document Type Declaration The document type declaration consists of markup code that indicates the grammar rules, or Document Type Definition (DTD), for the particular class of document. The document type declaration can also point to an external file that contains all or part of the DTD. The document type declaration must appear following the XML declaration and preceding the Document element. This code adds a document type declaration to the sample document:
<?xml version="1.0"?> <!DOCTYPE Wildflowers SYSTEM "Wldflr.dtd"> |
This statement tells the XML processor that the document is of the class Wildflowers and conforms to the rules set forth in the DTD file named Wldflr.dtd. (Chapter 4 discusses the idea of document classes and the details of the DTD.)
So ends the prolog. Following the prolog is the Document element, the heart of an XML document, where the actual content lives.
It might seem strange that a single element—the Document element—contains all the data in an XML document. However, this single element can comprise any number of nested subelements and external entities. It's similar to the C: drive on your computer. All the data on your computer is stored on that single drive. But any number of folders and subfolders keep the individual pieces of data in a (hopefully) logical and easy-to-manage structure.
This code adds a Document element (in this case, the Plant element) to the sample document:
<?xml version="1.0"?> <!DOCTYPE Wildflowers SYSTEM "Wldflr.dtd"> <PLANT> <COMMON>Columbine</COMMON> <BOTANICAL>Aquilegia canadensis</BOTANICAL> </PLANT> |
NestingNesting is the process of embedding one object or construct within another. For example, an XML document can contain nested elements and even other documents. Element nesting sets up parent/child relationships. Every child element (an element that is not the Document element) resides completely within its parent element. This can be represented as follows:
The following code, however, does not contain properly nested elements and will cause an error:
<DOCUMENT> <PARENT1> <CHILD1></CHILD1> <CHILD2></CHILD2> </PARENT1> </DOCUMENT>
<DOCUMENT> <PARENT1> <CHILD1></CHILD1> <CHILD2></CHILD2> </DOCUMENT> </PARENT1>
The physical structure of an XML document is composed of all the content used in that document. If you think of the logical structure as the blueprint for a parking garage, you can think of the physical structure as all the actual parking spaces within the garage. These parking spaces or storage units, called entities, can be part of the document or external to the document (like offsite parking for the airport). Each entity is identified by a unique name and contains its own content, from a single character inside the document to a large file that exists outside the document. In terms of the logical structure of an XML document, entities are declared in the prolog and referenced in the Document element.
An entity declaration tells the processor what to fill the "parking space" with. Once declared in the DTD, an entity can be used anywhere in the document. An entity reference tells the processor to retrieve the content of the entity, as declared in the entity declaration, and use it in the document.
An entity can be either parsed or unparsed. A parsed entity, sometimes called a text entity, contains text data that becomes part of the XML document once that data is processed. An unparsed entity is a container whose contents might or might not be text. If text, the content is not parsable XML.
Parsed Entities A parsed entity is intended to be read by the XML processor, so its content will be extracted. After it's extracted, a parsed entity's content appears as part of the text of the document at the location of the entity reference. For example, in our Wildflowers document, a light requirement (LR1) entity can be declared as
<!ENTITY LR1 "light requirement: mostly shade"> |
This declaration means "I am declaring an entity with the name LR1 that contains the content light requirement: mostly shade ." Whenever this entity is referenced in the document, it will be replaced by its content. You might now begin to see a benefit to using entities—if you want to change the content of the entity, you need to change it in only one place, the declaration, and the change will be reflected everywhere that the entity is used in the document.
Entity References As described above, the content of each entity is added to the document at each entity reference. The entity reference acts as a placeholder for the content author, and the XML processor places the actual content at each reference site. To include an entity reference, you first insert an ampersand (&) and then enter the entity name followed by a semicolon (;). So, to use our LR1 example above, we would insert &LR1;. Here's how it might look in a document:
<TERM>Wild Ginger has the following &LR1;</TERM> |
When that line is processed, the entity &LR1; will be replaced with the entity's content, so the line would read, "Wild Ginger has the following light requirement: mostly shade."
Parameter Entity References Another kind of entity reference is the parameter entity reference. A parameter entity reference uses a modulus (%) instead of an ampersand but otherwise looks identical to any other entity reference. %CDF; is an example of a parameter entity reference. The next chapter discusses parameter entities in detail.
Unparsed Entities An unparsed entity is sometimes referred to as a binary entity because its content is often a binary file (such as an image) that is not directly interpreted by the XML processor. Even so, an unparsed entity could contain plain text, so the term binary is a bit misleading. An unparsed entity requires different information from that included in a parsed entity: it requires a notation. A notation identifies the format, or type, of resource to which the entity is declared. Let's look at an example:
<!ENTITY MyImage SYSTEM "Image001.gif" NDATA GIF> |
This entity declaration literally means, "The entity MyImage is a binary file in the GIF notation"—a rather complex way of saying, "This is a GIF image." To make matters even more complicated, for these entity declarations to be valid, the notation must be declared as well. The notation declaration helps the XML application deal with these external, binary files. So for the GIF notation we used above, a notation declaration like this can be used:
<!NOTATION GIF SYSTEM "/Utils/Gifview.exe"> |
This tells the XML processor that whenever it encounters an entity of type GIF, it should use Gifview.exe to process it. As with other declarations, once declared, the notation declaration can be used throughout the document. We will examine this topic more closely in the next chapter.
NOTE
An entity reference should not contain unparsed entity names. Unparsed entities should be referred to only in attribute values of type ENTITY or ENTITIES. See the section "Opening and Closing Tags" later in this chapter for information about attributes and attribute values. See Chapter 4 for more information about attribute types.
In XML, certain characters are used specifically for marking up the document. For example, in the following element, the angle brackets (<>) and forward slash (/) are interpreted as markup and not as actual character data:
<PLANT>Bloodroot</PLANT> |
These and other characters are reserved for markup and cannot be used as content. If you want these characters to be displayed as data, they must be escaped. To escape a character, you must use an entity reference to insert the character into a document. So, for example, if you want to insert the text <PLANT> into a document, you would use this sequence:
<PLANT> |
In this example, the sequence < is the entity reference for the opening angle bracket (<), and the sequence > is the entity reference for the closing angle bracket (>).
Following are the entity references for all the predefined entities:
| Entity Reference | Character |
|---|---|
| < | < (opening angle bracket) |
| > | > (closing angle bracket) |
| & | & (ampersand) |
| ' | ' (apostrophe) |
| " | " (double quotation mark) |
NOTE
According to the W3C, all XML processors must recognize predefined entity references even if these entities are not declared. Even so, it is required that the entities be declared in the DTD for the document to be considered valid XML.
The preceding examples have demonstrated the difference between internal and external entities. An internal entity is one in which no separate physical storage unit exists; the content of the entity is provided in its declaration, as shown below:
<!ENTITY LR1 "light requirement: mostly shade"> |
An external entity refers to a storage unit in its declaration by using a system or public identifier. The system identifier provides a pointer to a location at which the entity content can be found, such as a URI (Uniform Resource Identifier), as shown here:
<!ENTITY MyImage SYSTEM "http://www.wildflowers.com/Images/Image001.gif" NDATA GIF> |
In this case, the XML processor must read the file Image001.gif to retrieve the content of this entity.
In addition to the system identifier, an entity can include a public identifier. The public identifier provides an additional, alternative way for the XML processor to retrieve the content of an entity. This identifier can be used if the application is connected to a publicly available document library, for example. If the processor is not able to generate an appropriate location from the public identifier, it must then check the URI specified by the system identifier.
NOTE
When discussing XML, the acronym URI is often used instead of the more familiar acronym URL (Uniform Resource Locator). In XML, a URI can be a Uniform Resource Name (URN) or a URL. The term URI is generally used to describe Web resources and is included in the XML specification as a matter of W3C (World Wide Web Consortium) policy. The W3C has the goal of generalizing pointers to Web resources and making URIs more common. For more information on URIs, please see http://www.w3.org/Addressing.
The following code shows the use of a public identifier:
<!ENTITY MyImage PUBLIC "-//Wildflowers//TEXT Standard images//EN" "http://www.wildflowers.com/images/image001.gif" NDATA GIF> |
A public identifier can be useful when working with an entity that is publicly available. The XML processor can check the public identifier against a list of resources to which it is connected and determine that it does not need to get a new copy of the entity because it is already available locally. However, until such public information storage mechanisms become more widely available, the system identifier will be more commonly used.
It might be helpful to summarize the different entity types. Here are the four types of entities we have covered:
From these, there are four possible combinations: