Desweiteren wird die Verschlüsselung einer Nachricht Y mit einem Schlüssel X, wird mit e(X,Y) angegeben und die Entschlüsselung einer Nachricht Y mit einem Schlüssel X als d(X,Y).
In dem Modell werden Protokollregeln in der Form
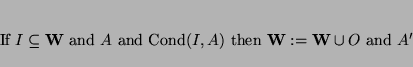
Solche Regeln können verschiedene Ereignisse beschreiben, wie
Beispiel 1
Eine Regel für einen Angreifer, der in der Lage ist, Daten zu verschlüsseln, kann so dargestellt werden:
Wie wir in Abschnitt 4 sehen werden, ist eine solche Angabe in der echten Spezifikation nicht nötig, da diese sich etwas von den theoretischen Grundlagen unterscheidet und solche Regeln von Analyzer selbstständig generiert werden.
Beispiel 2
Nehmen wir an ein Teilnehmer sendet alle Nachrichten die er bekommt mit dem
Sessionkey verschlüsselt weiter, so kann man das mit folgender Regel ausdrücken.
Neben den Regeln besteht ein Protokoll in diesem Modell aus einer Menge von Reduktionsregeln, welche die Umformung komplexerer Wörter in Einfachere beschreiben. Beispiele dafür sind
Definition 1: Spezifikation S eines Protokolls ist ein Tupel
![]() wobei
wobei
Definition 2: Term, Konstanten
Sei ![]() eine abzählbare Menge an Variablen und
eine abzählbare Menge an Variablen und ![]() eine endliche Menge
an Funktionssymbolen disjunkt von
eine endliche Menge
an Funktionssymbolen disjunkt von ![]() mit zugehöriger arity (Anzahl
der Funktionsparameter).
Dann ist ein Term entweder eine Variable aus
mit zugehöriger arity (Anzahl
der Funktionsparameter).
Dann ist ein Term entweder eine Variable aus ![]() oder ein Funktionsymbol
gefolgt von
oder ein Funktionsymbol
gefolgt von ![]() Termen, wobei n die arity des Funktionssymbols angibt.
Ein Funktionssymbol mit einer arity von null ist eine Konstante.
Termen, wobei n die arity des Funktionssymbols angibt.
Ein Funktionssymbol mit einer arity von null ist eine Konstante.
Definition 3: Substitution, Unifikator
Sei ![]() die Menge von Termen ist, die durch
die Menge von Termen ist, die durch ![]() und
und ![]() gebildet
werden kann. Dann ist eine Substitution eine Funktion von
gebildet
werden kann. Dann ist eine Substitution eine Funktion von ![]() in
in
![]() .
Der Term den man durch Anwendung einer Substitution
.
Der Term den man durch Anwendung einer Substitution ![]() auf die Variablen
eines Terms
auf die Variablen
eines Terms ![]() erhält, wird durch
erhält, wird durch ![]() angegeben.
angegeben.
Ein Unifikator von zwei Termen ![]() und
und ![]() ist eine Substitution
ist eine Substitution ![]() ,
so daß
,
so daß
![]() . Es werden also 2 Terme durch entsprechende
Substitution in den gleichen Term umgewandelt.
Der allgemeingültigste Unifikator von
. Es werden also 2 Terme durch entsprechende
Substitution in den gleichen Term umgewandelt.
Der allgemeingültigste Unifikator von ![]() und
und ![]() ist ein Unifikator
ist ein Unifikator ![]() , so daß, wenn es einen weiteren Unifikator
, so daß, wenn es einen weiteren Unifikator ![]() gibt, es noch ein weiter Unifikator
gibt, es noch ein weiter Unifikator ![]() existiert, so daß gilt
existiert, so daß gilt
![]() .
.
Definition 4: term-rewriting system, Normalform
Ein term-rewriting system über ![]() ist eine Menge gerichteter Gleichungen
ist eine Menge gerichteter Gleichungen
![]() , so daß für
, so daß für
![]() in
in ![]() ,
,
![]() gilt, wobei V(T) die Menge der Variablen in T angibt.
gilt, wobei V(T) die Menge der Variablen in T angibt.
Wenn ein Term A in einen eindeutigen nicht reduzierbaren Term durch die Anwendung von Reduktionsregeln gebracht werden kann, so nennt man den erzeugten Term Normalform von A (nf(A)).
Für den Analyzer sind term-rewriting systems interessant, die Noetherian und locally confluent sind. Diese haben die Eigenschaft, daß jeder Term A zu einer eindeutigen nicht mehr weiter reduzierbaren Normalform nf(A) reduzierbar ist.
Definition 5: Noetherian, locally confluent
Sei ![]() ein term-rewriting sytem über
ein term-rewriting sytem über ![]() .
. ![]() ist
Noetherian, wenn ein Term A, der von einem Term B mittels der
Anwendung von Reduktionsregeln erreichbar ist, innerhalb einer endlichen
Anzahl von Schritten erreicht wird.
ist
Noetherian, wenn ein Term A, der von einem Term B mittels der
Anwendung von Reduktionsregeln erreichbar ist, innerhalb einer endlichen
Anzahl von Schritten erreicht wird.
![]() ist locally confluent, falls wennimmer ein Term A zu den
Termen B und C
mittels zwei verschiedener Reduktionsregeln reduzierbar ist, dann sind B und C
beide zu einem gemeinsamen Term D reduzierbar.
ist locally confluent, falls wennimmer ein Term A zu den
Termen B und C
mittels zwei verschiedener Reduktionsregeln reduzierbar ist, dann sind B und C
beide zu einem gemeinsamen Term D reduzierbar.
Beispiel 3
Solch ein term-rewriting system kann zum Beispiel wie folgt aussehen. Es
handelt sich wieder um die triviale Aufhebung von Ver- und Entschlüsselung
mit dem selben Key.
![]()
![]()
Es folgen Grundlagen für das Zustandsmodell, es wird beschrieben, was ein Systemzustand und was eine Zustandsbeschreibung ist und wie man eine Zustandsbeschreibung von einer Anderen erreicht.
Definition 6: Systemzustand und Zustandbeschreibung
Ein Systemzustand ist ein Paar (
![]() ), wobei
), wobei ![]() die
Menge der Wörter ist, die der Angreifer kennt und
die
Menge der Wörter ist, die der Angreifer kennt und
![]() den Zustandsvariablen
(
den Zustandsvariablen
(![]() ) die Werte (
) die Werte (![]() ) zuordnet.
) zuordnet.
Eine Zustandsbeschreibung (![]() ) ist ein Paar, so daß
) ist ein Paar, so daß ![]() eine Menge an
Termen aus
eine Menge an
Termen aus ![]() ist und
ist und
![]() ist
die Zuordnung einer Menge von Termen aus
ist
die Zuordnung einer Menge von Termen aus ![]() (
(![]() ) zu den Zustandsvariablen (
) zu den Zustandsvariablen (![]() ).
).
Ein Systemzustand (
![]() ) genügt einer Zustandsbeschreibung
(
) genügt einer Zustandsbeschreibung
(![]() ), wenn alle Terme in (
), wenn alle Terme in (
![]() ) nicht reduzierbar sind und es
eine Substitution
) nicht reduzierbar sind und es
eine Substitution ![]() gibt, so daß
gibt, so daß
![]() und
und
![]() .
.
Beispiel 4
Nehmen wir die Zustandsbeschreibung (e(k,X),). Dann können wir annehmen, daß
der Angreifer ein word e(k,![]() X) kennt, wobei die Substitution X einen
Term zuweist, so daß e(k,
X) kennt, wobei die Substitution X einen
Term zuweist, so daß e(k,![]() X) nicht weiter reduziert werden kann.
Daher könnte er e(k,m) oder e(k,e(l,m)) kennen, nicht aber e(k,d(k,m)).
X) nicht weiter reduziert werden kann.
Daher könnte er e(k,m) oder e(k,e(l,m)) kennen, nicht aber e(k,d(k,m)).
Die Annahme, daß Term (im Beispiel e(k,![]() X)) nicht weiter reduzierbar
ist, ist daher wichtig, weil wenn der Angreifer e(k,
X)) nicht weiter reduzierbar
ist, ist daher wichtig, weil wenn der Angreifer e(k,![]() X) kennt und
X=d(k,Y) sein könnte, sich das ganze zu Y reduzieren würde und man daraus
erfahren würde, daß der Angreifer irgendein Y kennt. Und zu der Zustandsbeschreibungdiese nutzlose Information hinzukommen würde.
X) kennt und
X=d(k,Y) sein könnte, sich das ganze zu Y reduzieren würde und man daraus
erfahren würde, daß der Angreifer irgendein Y kennt. Und zu der Zustandsbeschreibungdiese nutzlose Information hinzukommen würde.
Eine Protokollregel kann nun interpretiert werden, um von einer Zustandsbeschreibung zu einer Weiteren zu gelangen. Die Bedingungen der Regel müssen von einer Zustandsbeschreibung erfüllt sein, damit die Regel angewandt wird. Mit der Folgerung aus der Regel wird die neue Beschreibung konstruiert.
Definition 7: Übergange zwischen Zustandsbeschreibungen
Seien (![]() ) und (
) und (![]() ) Zustandsbeschreibungen. Dann sei R eine Regel
der bekannten Form
) Zustandsbeschreibungen. Dann sei R eine Regel
der bekannten Form
Beispiel 5
Gehen wir davon aus, daß der Angreifer das Wort ``message`` kennt und
KEYSTATE(a):=key1, dann kann die Regel
Man kann nun verfolgen wie durch Anwendung der Prokollregeln man von einem Zustand zum nächsten gelangt. Um zu Bestimmen, ob ein Protokoll sicher ist soll gezeigt werden, daß man von bestimmten Zuständen nicht den Initialzustand erreichen kann. Was nun folgt ist genau der umgekehrte Schritt. Es muss anhand der Zustandsbeschreibung bestimmt werden, welche andere Zustandsbeschreibungen die Zustände beschreibt, die direkt davor gewesen sein könnten. Dazu wird im Prinzip die Folgerung jeder Regel mit der Zustandsbeschreibung unifiziert.
Sei die Zustandsbeschreibung (![]() ) gegeben. Man sucht nun eine Substitution
) gegeben. Man sucht nun eine Substitution
![]() , die
, die ![]() ,
, ![]() und (
und (![]() ) so umformt, daß diese nicht weiter
reduzierbar sind und im weiteren gilt
) so umformt, daß diese nicht weiter
reduzierbar sind und im weiteren gilt
Daraus ergibt sich ein vorheriger Zustand (![]() ), in dem der Angreifer
), in dem der Angreifer
![]() kennt und die Menge der
Zustandsvariablen
kennt und die Menge der
Zustandsvariablen
![]() entspricht,
wobei
entspricht,
wobei ![]() alle Zuweisung aus
alle Zuweisung aus ![]() enthält.
enthält.
Der Analyzer muss nun alle möglichen Substitutionen ![]() finden, die
die Zustandsbeschreibung mit der Folgerung einer Regel unifiziert. Davon
gibt es oft eine unendliche Menge, jedoch eine endlich, ausreichende Menge
(complete set), mit deren Hilfe man alle anderen Unifikatoren bilden kann.
Zu der Bestimmung solcher Mengen gibt es einige Algorithmen. Da von
dem term-rewriting Sytem verlangt wird, daß es Noetherian und locally
confluent ist, kann man mit Hilfe eines Algorithmus aus der Klasse der
,,narrowing algorithms`` diese Menge bestimmen. Im Fall des Analyzers
wurde eine modifizierte Version des NARROWER Algorithmus [5]
eingesetzt, um anhand einer Protokollbeschreibung und der Beschreibung
eines Systemzustandes, die Menge der Beschreibungen zu finden, die diesem
direkt vorangehen können.
finden, die
die Zustandsbeschreibung mit der Folgerung einer Regel unifiziert. Davon
gibt es oft eine unendliche Menge, jedoch eine endlich, ausreichende Menge
(complete set), mit deren Hilfe man alle anderen Unifikatoren bilden kann.
Zu der Bestimmung solcher Mengen gibt es einige Algorithmen. Da von
dem term-rewriting Sytem verlangt wird, daß es Noetherian und locally
confluent ist, kann man mit Hilfe eines Algorithmus aus der Klasse der
,,narrowing algorithms`` diese Menge bestimmen. Im Fall des Analyzers
wurde eine modifizierte Version des NARROWER Algorithmus [5]
eingesetzt, um anhand einer Protokollbeschreibung und der Beschreibung
eines Systemzustandes, die Menge der Beschreibungen zu finden, die diesem
direkt vorangehen können.
Beispiel 6
Nehmen wir als Beispiel eine Spezifikation mit der einen Regel
Es werden dann 2 Elemente der Menge gefunden und zwar Q:=e(X,Y) und Y:=d(X,Q).
Wendet man die 1. Unifikation an erhält man die Bedingungen
![]() and KEYSTATE(
and KEYSTATE(![]() und der Angreifer lernt das Wort Q:=e(X,Y), der
Vorgängerzustand war demnach (Y, KEYSTATE(
und der Angreifer lernt das Wort Q:=e(X,Y), der
Vorgängerzustand war demnach (Y, KEYSTATE(![]() ). Bei der 2.
erhält man
). Bei der 2.
erhält man
![]() and KEYSTATE(Z)=X und der Angreifer lernt
das Wort Q (e(X,Y)=e(X,d(X,Y))), der Vorgängerzustand ist demnach
(d(X,Q), KEYSTATE(
and KEYSTATE(Z)=X und der Angreifer lernt
das Wort Q (e(X,Y)=e(X,d(X,Y))), der Vorgängerzustand ist demnach
(d(X,Q), KEYSTATE(![]() )
)
Beispiel 7
Als zweites Beispiel dieselbe Spezifikation mit der einen Regel
Ziel des Programmes ist es nun zu zeigen, daß ein Startzustand nicht von einem definierten unsicheren Zustand zu erreichen ist. Würde man das ganze ohne Einschränken durchführen, würde schnell ein unüberschaubare Menge an Zuständen entstehen, meist in Endlosschleifen endend. Man braucht also zum einen Techniken um die Suche einzuschränken und zum anderen zu Zeigen, daß ein Zustand der irgendwo in einer Endlosschleife entsteht kein Startzustand sein kann. Um ein Protkoll zu analysieren, wird nun eine Protokollspezifikation erstell, die unsicherne Zustände bestimmt und gezeigt, daß ein Menge von Zuständen unerreichbar ist. Dann wird über die restlichen Zustände ein komplette Suche laufen gelassen. Hier wird nun noch beschrieben, wie Zustände mit Hilfe formaler Sprachen als unerreichbar bestimmt werden.