Humboldt Universität zu Berlin
Institut für Informatik
IRISERKENNUNG
Vortrag
von Elena Filatova und Roman
Keller
zum Seminar
„Biometrische Identifikationsverfahren“
Dozenten:
Prof.
Johannes Köbler und Matthias
Schwan
SS2004
Berlin
3. Der Algorithmus von John Daugman
3.2 Extraktion der Iris aus dem Bild
3.4 Problem: Position, Größe und Orientierung
3.4.1 Optische Größe der Iris und Größe der Pupille
3.4.3 Orientierung und Körperhaltung
3.5 Mustercode- / Iriscodevergleich
4. Theoretische Wahrscheinlichkeiten
6.2.2 Physischer-Zugriff Systeme
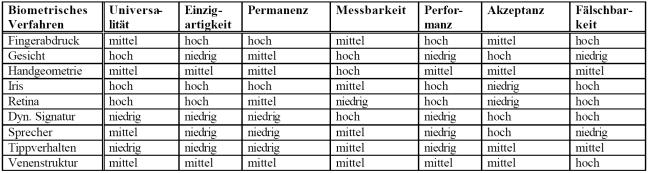
10. Vergleichstabellen von
biometrischen Verfahren
10.1 Bewertung der biometrischen Verfahren in
bezug auf generelle biometrische Anforderungen
10.3 Bewertung der biometrischen Verfahren in
bezug auf Anwendungsumgebungen
1. Ein bisschen Geschichte
1983: Der James-Bond-Film "Sag
niemals nie" flimmert weltweit über die Leinwände der Kinos: Am Auge eines
durch seine Drogensucht erpressbar gewordenen Offiziers der US Air Force wird
eine "Hornhauttransplantation" vorgenommen, um den per Augenscanning
realisierten Zugriffsschutz für den Austausch von Gefechtsattrappen durch
Nuklearsprengköpfe zu überlisten. Diese Befugnis ist nämlich einzig dem
amerikanischen Präsidenten vorbehalten und so ist das Transplantat folgerichtig
eine "Nachbildung" dessen Auges.
1993: Der Algorithmus von John
Daugman zur Erkennung der Iris.
1998:
Olympische Winterspiele im japanischen Nagano: Die Biathleten gelangen nur dann
in die Waffenkammer und damit an die zu ihrer Disziplin notwendigen - in
falschen Händen durchaus gefährlichen - Sportgeräte, wenn das biometrische
Muster ihrer Iris/Regenbogenhaut mit dem zuvor individuell gespeicherten
Referenzmuster übereinstimmt. Was in dem zuvor erwähnten Film noch als Fiktion
erscheinen mochte, ist Realität geworden.
2. Biologischer Hintergrund
Abb. Aufbau des Auges

An den Augapfel
schließt sich nach vorne die Regenbogenhaut (Iris) an. Durch ihr kreisrundes
Loch, die Pupille, fällt das Licht ins Auge. Der Rand der Pupille liegt auf der
Linse auf. Die Iris wirkt wie eine Lichtblende eines Photoapparates und kann
durch Weit- oder Engstellung den Lichteinfall ins Auge regulieren. Diese
Vergrößerung oder Verkleinerung der Pupille erfolgt durch Muskeln innerhalb der
Regenbogenhaut. Die Pupillenweite kann zwischen ca. 8 und 1,5mm variieren. So
wird bei Dunkelheit die Pupille vergrößert und im grellen Licht enggestellt.
Die Regenbogenhaut besteht
aus Bindegewebe und Muskulatur zum
Schließen der Pupille, sie hat kein vorderes Epithel (wahrscheinlich einzige
Stelle im Körper).
Die Iris hat zwei Lagen,
eine äußere, die Pigmente enthält (wenn dicht, dann braune Augen, wenn weniger
dann grüne, wenn noch weniger schimmern die Blutadern darunter durch, so dass
die Augen blau wirken, wenn alle Pigmente fehlen: Albino), und eine innere, die
Blutadern enthält. Die „Augenfarbe„ wird vererbt und ändert sich teilweise nach
der Geburt. Jeder Mensch hat eine individuelle und einmalige Augenfarbe.
Die Entwicklung der Iris
setzt im 3. Schwangerschaftsmonat ein, im 8. Schwangerschaftsmonat ist die Iris komplett ausgebildet.
Zu den Merkmalen eines
Irismusters zählen feine Erhöhungen, Furchen, Flecken, Ringe, Corona usw., man
kann mehr als 400 individuell verschiedene Merkmale unterscheiden,
dass ist acht mal mehr als bei einem Fingerabdruck.
Im Jahr 2001 wurde an der
Cambridge Universität eine Studie durchgeführt , dabei wurden mehr als 2 Mio.
Bilder verglichen [9].
Abb. Verteilung des
Hamming Abstand bei dem Vergleich von Irismuster von 2,3 Mio. Menschen
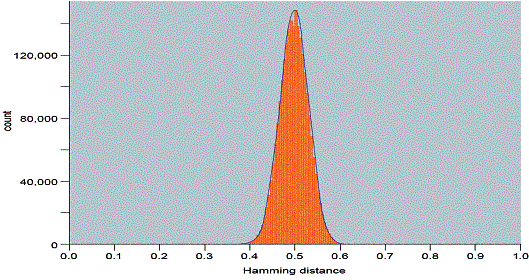
Bei dem Vergleich stießen die Forscher auf keine einzige Doppelung. Das Muster der Iris bildet sich im Gegensatz zur Pigmentation zufällig und ist genetisch unabhängig, deshalb lassen sich dadurch selbst genetisch identische Augen unterscheiden. Die genetisch identischen Zwillinge, bzw. das rechte und das linke Auge einer einzelnen Person haben so unterschiedliche Codes, wie zwei völlig verschiedene Menschen. Die Wahrscheinlichkeit , dass die Iris zweier Menschen zufällig übereinstimmen, liegt bei ca. 1 zu 10^1078 [10]
Abb. Verteilung von
Hamming Abschtand bei dem Vergleich des linken und des rechten Auges bei
324 Personen.
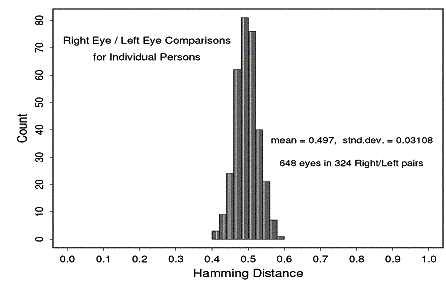
Die Iris ist ein stabiles
Merkmal, falls keine mechanische Schaden auftreten, bleiben die Muster ein
Leben lang erhalten. Bilder einer Iris, im Abstand von 25 Jahren aufgenommen,
können nicht von einander unterschieden werden. Außerdem wird das Auge, und die
Iris mit ihm, ein Leben lang besonderes gut geschützt. Das liegt nicht nur an
der menschlichen Natur. Das Auge ist
durch den menschlichen Schädel, durch die Lederhaut und durch die Hornhaut gut
geschützt. Die Veränderungen der Iris können durch mechanische Schäden und
durch verschiedene Krankheiten (u.a. Augenkrankheiten) verursacht werden. Das
Irismuster bleibt weitgehend von den Veränderungen durch Krankheiten verschont, da hauptsächlich die Pigmentation
des Auges bei Krankheiten geändert wird.
Noch eine Besonderheit des
Auges macht die Irismustererkennung besonders interessant. Die Augen eines
Toten sind leicht zu unterscheiden von den Augen lebender Personen ( Die
Pupille dehnt sich auf über 80 % aus und der Augapfel wird sehr matt und trübe)
Zusammenfassung:
Das Irismuster ist ein
1. sehr
stabiles (hält ein Leben lang)
2. sicheres ( weil
-
unterschiedlich selbst bei
genetisch gleichen Augen und
-
leicht zwischen dem Auge
eines Lebenden und eines
Toten zu unterscheiden)
Merkmal des Menschen.
3. Der Algorithmus von John Daugman
Fast alle kommerzielle Produkte für Iriserkennung,
die es heutzutage auf dem Markt gibt, basieren auf dem Algorithmus von John
Daugman [http://www.cl.cam.ac.uk/users/jgd1000] von der University of Cambridge, Institute of Mathematics
and Informatics.
Sein Algorithmus durchläuft folgende Schritte ab:
- Bildaufnahme
eines Auges
- Extraktion
der Iris aus dem Bild
- Umwandlung
des Musters in eine digitale Form 2048 Bit lang (Codierung)
- Bitweiser
Vergleich der aufgenommener Iris mit einem vorhandenen Code
3.1 Gewinnung des Bildes
Der
Ablauf einer Bildaufnahme hängt von den verwendeten Geräten ab, welche in dem
Kap. „Produkte und Anwendungen“ dargestellt werden.
Nachdem eine geeignete, der Irisradius muss mindestens 70 Pixel aufweisen (üblich sind jedoch 100-140 Pixel), Aufnahme des Auges erfolgreich abgeschlossen wurde, kann die eigentliche Verarbeitung des Bildes stattfinden.
3.2 Extraktion der Iris aus dem Bild
Nun wird mit Hilfe
folgender Formel die Iris in dem gegebenen Bild dadurch lokalisiert, dass man
den Radius für die Pupille und für den äußeren Rand der Iris berechnet:
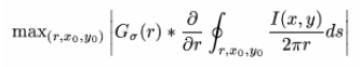
Das
Kreisintegral berechnet dabei für jeden Mittelpunkt (x0,
y0) den Mittelwert der
Bildpunkte, die auf dem von Radius r
erzeugten Kreis liegen, wobei r
schrittweise erhöht wird. Diese Mittelwerte werden anschließend partiell nach r abgeleitet und mit einem Gaußfilter G
geglättet. Angenommen x0
und y0 lägen
genau in der Pupillenmitte, so würde man für Kreislinien, die sich bis zur
Pupillengrenze ausdehnen, Mittelwerte von etwa 0 erhalten. Für den ersten
Kreis, dessen Kreislinie auf die Iris fällt, würde ein höherer Mittelwert
berechnet werden, da die Iris hellere Farbwerte hat. Betrachtet man die
Mittelwerte bei zunehmendem Radius als Graph, so ist der Übergang zwischen
Pupille und Iris als starker Anstieg der Funktion zu erkennen (siehe Abb.). Der
Punkt (x0, y0),
für den dieser Übergang am stärksten ist (erkenntlich durch die Ableitung nach r), wird als Mittelpunkt bestimmt. [1]
Abb. Mittelwerte (1) und Ableitung der Mittelwerte
(2)

Um genaue Werte zu bekommen
muss diese Methode separat für den Übergang Iris/Sclera (weiße Augenpartie)
angewendet werden, da die Pupille nicht exakt in der Mitte der Iris liegt.
3.3 Iriscode Generierung
Nun, da man die Position
der Iris kennt, ist es möglich den digitalen Iriscode zu generieren. Doch zuvor findet eine Abbildung des Irisringes auf eine beschränkte Ebene statt,
die ein Irisring in Polardarstellung (siehe Abb. unten) umwandelt:
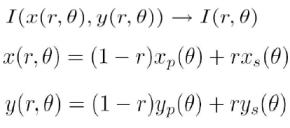
Dabei
wird die Breite der Iris normiert und der Radius in der obigen Abbildung
bekommt die Werte aus dem Intervall [0,1] (0 – der Punkt liegt an der Grenze
Pupille-Iris, 1 – der Punkt liegt an der Grenze Iris-Sclera).

Somit ist die tatsächliche
Größe der Iris und die Ausdehnung der Pupille während der Bildaufnahme nicht
mehr stören. Und der Informationsgehalt bleibt erhalten (siehe Kap.
„Biologischer Hintergrund“).
Jetzt erfolgt die
eigentliche Digitalisierung der Iris, oder Erzeugung des Iriscodes über
Gaborwavelets, angewendet an die Polardarstellung:
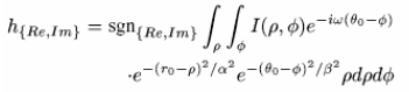
Jeder Berechnungsschritt,
der mit dieser Formel ausgeführt wird, setzt zwei Bits des Iriscodes. Für das
Setzen der Bits ist der Signum-Operator (sgn)
verantwortlich. Dieser nimmt per Definition eine reelle Zahl an und gibt, je
nach Vorzeichen dieser Zahl, entweder 1, falls die Zahl positiv ist, oder 0,
falls die Zahl kleiner oder gleich Null ist, zurück. In der oben angegeben
Formel wird der Operator auf eine komplexe Zahl angewendet. Dieses entspricht
einer jeweils separaten Anwendung des Operators auf den Real- und den
Imaginärteil der Zahl. Deswegen ist das Ergebnis einer Anwendung dieses
Operators ein Zwei-Tupel. [8]
Abb. Iriscode

Nachdem das Wavelet auf das polare Irisbild
angewendet wurde, erhält man 2048 Bits (256 Byte). Zusätzlich zu diesen Bits
werden noch 2048 Maskenbits mit abgespeichert, die angeben, ob die betreffende
Position durch Artefakte beeinträchtigt wurde (z.B. Wimpern oder Reflexionen).
Insgesamt erhält man also 512 Byte Iriscode. [1]
3.4 Problem: Position, Größe und Orientierung
Nun betrachten wir einige Problemstellungen, die
auf das Resultat eines Iriserkennungsvorganges negativen Einfluss nehmen
können. Dazu zählen optische
Größe der Iris auf dem Bild, die von der Zoomeinstellungen einer Kamera und der
Entfernung des Objektes zur Kamera abhängig ist, Größe der Pupille im Auge,
abhängig von der umgebenden Beleuchtung, Position der Iris auf dem Bild und
Ausrichtung der Iris, die von der Kopf- und Körperhaltung abhängig sind. Diese
Aspekte stellen ein Problem für einen funktionierenden Algorithmus dar und
sollen deshalb vor dem eigentlichen Ablauf der Iriserkennung beseitigt bzw.
ausgeglichen werden.
3.4.1 Optische Größe der Iris und Größe der Pupille
Die Größe der Pupille
spielt hierbei keine Rolle, da bei deren Vergrößerung die Iris nicht verdeckt
wird, sonder sich lediglich zusammenzieht und der Merkmalsbestand bleibt
unverändert erhalten.
Die Größe der Iris hat
ebenfalls keine dramatischen Auswirkungen, da die Iris durch ein
Polarkoordinatensystem dargestellt und dabei ausgeglichen wird. Das heißt, dass wenn das Irismuster auf dem
Bild seine Größe ändert, wird das relative Muster in Polardarstellung gleich
bleiben (siehe Kap. „Algorithmus von John Daugman“).
3.4.2 Ausrichtung der Iris
Die
Rotation des Auges wird dadurch korrigiert, dass die Pixelzeilen des Irisbildes
in Polarkoordinaten jeweils um einige Pixel „geshiftet“ werden. Eine
Verschiebung um K Pixel entspricht dabei einer
drehung um
K · 360°/M
wobei
M die Anzahl an Pixelspalten in der Polardarstellung ist. Zu jedem rotiertem Bild
wird der Code berechnet und dasjenige Bild im Weiteren verwendet, das die beste
Hamming Distanz zu den anderen Codes besitzt. (Laut Daugman reichen i.d.R.
bereits 7 Verschiebungen aus). [5]
3.4.3 Orientierung und Körperhaltung
Eine falsche Körperhaltung
eines Nutzers kann von einem intellektuell implementierten System durch
Interaktionen mit dem Nutzer vorgebeugt bzw. korrigiert werden.
3.5 Mustercode- / Iriscodevergleich
Da die Iriserkennug
normalerweise nicht unter idealen Bedingungen stattfindet, wird die
Wahrscheinlichkeit für eine komplette Übereinstimmung der zwei identischen
Muster nicht bei 100 % liegen. Der Vergleich
wird von Rauschen, Reflexionen, Bewegungen des Menschen beeinflusst.
Als Maß für die
Ähnlichkeit zweier Iriscodes wird bei Daugman die normierte Hammingdistanz
(Hamming Abstand) HD benutzt:
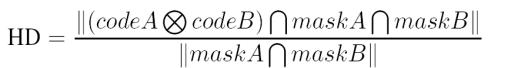
Hierbei codeA und codeB
sind zu vergleichende Wörte (2048 Bits Vektoren), maskA, maskB – die Masken,
die angeben welche Bereiche nicht berücksichtigt werden XOR (exklusiv
Oder) vergleicht zwei Bitvektoren,
wobei eine Nichtübereinstimmung eine 1 liefert. Der Schnitt (AND-Operator) mit
den Masken beschränkt den Vergleichsbereich (im Zähler) und der Schnitt im
Nenner dient der Normierung.
Zusammengefasst
die 1-en, die durch XOR-Funktion ermittelt wurden, werden zusammengezählt und durch die Anzahl der zu vergleichenden Bits geteilt – so wird das Maß an Ähnlichkeit bestimmt.
HD kann zwischen 0 und 1
liegen, wobei die 0 der absoluten Übereinstimmung entspricht und die 1 ein
Ergebnis des Vergleiches zweier absolut unterschiedlicher Muster ist .
Wegen vieler Faktoren, die
das Bild verfälschen können, braucht man den bestimmten Freiheitsgrad.
Andererseits kann eine zu hoch gesetzte Schwelle zu falschen Ergebnissen
führen.
Bis heute wurde der
Algorithmus in Japan, USA, Deutschland und UK eingesetzt. Bei den Feldversuchen
wurde kein Muster falsch identifiziert, aber es gab die Muster, die
fälschlicherweise nicht erkannt wurden.
4. Theoretische Wahrscheinlichkeiten
In der Praxis interessiert
man sich für die Anwendung der Iriserkennug mit großen Datenbanken. Die Frage,
die daraus folgt, ist, ob und wie zuverlässig die Iriserkennug dabei wird. Wenn ![]() die
Wahrscheinlichkeit für die falsche Identifizierung ist, dann ist
die
Wahrscheinlichkeit für die falsche Identifizierung ist, dann ist
![]()
die Wahrscheinlichkeit für
eine falsche Identifizierung in einer Datenbank mit n Einträgen.
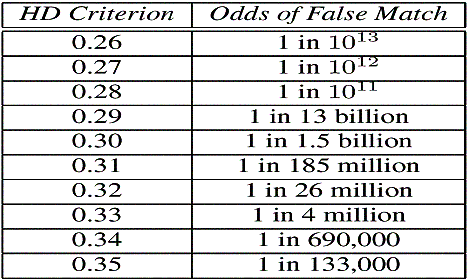
Man kann die Schwelle für
HD je nach Größe der Datenbanken wählen, um so die Wahrscheinlichkeit des
Fehlers klein zu halten.
Tabelle:
Wahrscheinlichkeit für eine falsche Identifizierung für feste HDs [6]
5. Entscheidungsumgebung
Das wichtigste Kriterium für die Iriserkennug und Identifikation ist die Bestimmung der Schwelle der HDs. Die Entscheidung, ob es sich um zwei gleiche oder zwei verschiedene Muster handelt, wird durch den Vergleich der ermittelten HD mit dem Schwellenwert getroffen. Man erhält zwei verschiedene Verteilungen, eine für den Vergleich von identischen Irismustern und eine für den Vergleich von unterschiedlichen Irismustern. Setzt man die Schwelle auf den Schnittpunkt dieser Verteilungen, wird in dem Punkt die False Accept Rate gleich die False Reject Rate sein.
Verkleinert man den Wert der HD, der als Schwelle dient, wird
die Wahrscheinlichkeit sinken, dass eine
nicht autorisierte Person einen beispielsweise für sie unerlaubten
Zugriff bekommt.
Abb. Verteilung HD bei
Vergleich zweier Muster gleicher Augen (blau) und zweier Muster
verschiedener Augen (rot) [11]
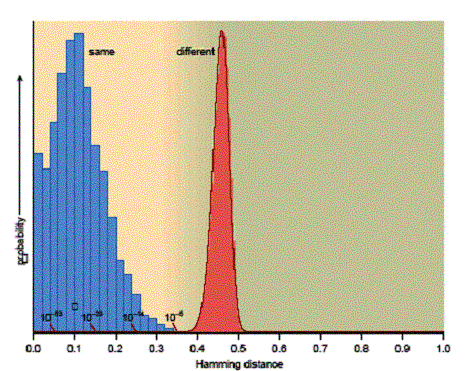
Anderseits steigt die
Wahrscheinlichkeit, dass eine autorisierte Person zurückgewesen wird.
Da es in den
Laborversuchen von J. Daugman keine falschen Entscheidungen gab, wenn die
Schwelle auf der 0,33 gesetzt wurde [6], wird
dieser Wert als mögliche Orientierung vorgeschlagen. Es ist klar, dass bei
großen Datenbanken dieser Wert verkleinert werden muss, um den
Sicherheitsstandard aufrecht zu erhalten.
Überraschenderweise ändern die schlechten Aufnahmebedingungen des
Irismusters die Sicherheit der Identifizierung nicht, da die Übereinstimmung
der Vergleichsbitpaare der verschiedenen Muster zufällig verteilt ist, genauso
wie die Störungen. Die Wahrscheinlichkeit einer „false nonmatching“
steigt dagegen. Um dies zu minimieren macht man mehrere Aufnahmen der Iris nach
einander (so genannte Signalmittelung), dadurch wird die Anzahl der zufälligen
Informationen, die z.B. durch Rauschen entstanden sind, verkleinert.
6. Produkte und Anwendungen
6.1 Komponenten
Im Allgemeinen bestehen
Iriserkennungssysteme aus Front-End Hardwarekomponente und Back-End lokalen
oder zentralen Softwarekomponente. [3]
Im Gegensatz zu
Gesichtserkennungssystemen, welche sich auf normale existierende Kameras
stützen, benötigen Iriserkennungssysteme notwendigerweise spezielle Geräte, die
infrarote Beleuchtung des Auges durchführen. Das hat den Vorteil, dass die
dunkelpigmentierte Iriden sich im Bild doch noch erkennen lassen und man deren
reichhaltige komplexe Muster erhält, außerdem bekommt man allgemein eine
deutlichere Abbildung einer Iris, da auch Störungen durch Lichtreflexionen
abgeschwächt werden. In der Regel basieren Iriserkennungssysteme auf
monochromatischen Kameras.
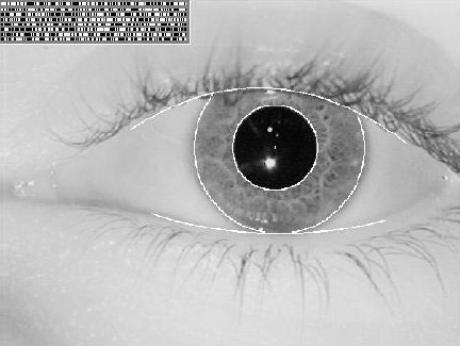
In Abbildung ist ein solches gescanntes Bild einer Iris bei
einem Wellenlängenbereich von 700 nm bis 900 nm (NIR-Bereich – nahe Infrarot
Bereich) dargestellt. [2]
Abb. Irisbild bei
einer NIR-Aufnahme.
Softwarekomponente eines
Iriserkennungssystem, wie Bearbeitung des Irisbildes, Matching-Engine, oder die
Datenbankverwaltung, können auf einem lokalen PC nah zur
Bildgewinnungskomponente residieren, oder sich auf lokale und zentrale Rechner
verteilen.
In z.B. einem
netzwerkbasiertem Sicherheitssystem ist ein zentraler Server, oder
Back-End-Komponente, für das Vergleichen (matching) und Abspeichern (store) der
Daten und eine Front-End-Komponente mit einer integrierten Rechnereinheit für
das generieren der Templates zuständig.
Iriserkennungssysteme sind
aus Sicherheitsgründen nie Web-angeschlossen. [3]
6.2 Front-End-Komponenten
Der Prozess der
Bildgewinnung an sich und die damit verbundene Bemühungen erfordern
unterschiedliche Typen einer
Bildgewinnungskomponente.
Es existieren drei
Haupttypen eines Iriserkennungssystems: Kiosk-Basierte Systeme,
Physischer-Zugriff Systeme, Desktop-Kamera Systeme. [3]
Abb. Ticketing System EyeTicket der EyeTicket Corporation. Kiosk System.

6.2.1 Kiosk-Basierte Systeme
Kiosk-Basierte Systeme
erfordern, dass der Nutzer in einer Entfernung von etwa 0.6 bis 1 Meter von
der oder den Kameras steht, welche in ungefähren Höhe seiner Augen
angebracht sind. Der Nutzer muss möglichst still bei dem Scannvorgang stehen
bleiben, weil solche Systeme nicht an Lokalisierung der beweglichen Ziele
angepasst sind. Wenn das Gesicht des Nutzers richtig lokalisiert ist,
beginnt das System nach Augenformen zu suchen. Sind weiterhin diese
lokalisiert, verläuft der restlicher Vorgang der Irisbildgewinnung
automatisch weiter. Der Vorgang der Iriserkennung dauert normalerweise 1-2
Sekunden.
6.2.2 Physischer-Zugriff Systeme
Solche
Systeme erwarten deutlich mehr Aktionen von einem Nutzer. Eine kleine Kamera,
die hinter einem Spiegel untergebracht ist, ist hier zuständig für
Bildgewinnung. Der Nutzer wird aufgefordert Sein Auge in dem Spiegel zu
positionieren und seine Iris in einem 1x1 Zentimeter großen Quadrat zu
zentrieren. Eventuell können solche Systeme über eine Nutzernavigation per
Sprache oder Schrift verfügen, um eine bestmögliche Position des Nutzers vor
der Kamera zu erreichen, was allerdings einen Nachteil solcher Systeme
darstellt, da längst nicht alle Nutzer in der Lage wären den Hinweisen eines
automatisierten Systems aus unterschiedlichen Gründen zu folgen. Daher bietet
sich der Einsatz von solchen Systemen nur in einem geschlossenen Benutzerkreis,
Gemeinschaft, oder Umgebung.
Der erwünschte Abstand
eines Nutzers zu der Kamera, angesichts der geeigneten Bildqualität und
/-Auflösung, beträgt 3 Zentimeter. Eine high-quality Kamera fokussiert sich
dann auf die Augen und schießt eine Serie von Bildern bis ein passendes
erreicht wurde.
Abb. Physical Access System.

6.2.3 Desktop-Kamera Systeme
Desktop-Kamera Systeme sind
neuster Typ der Iriserkennungssysteme und werden für logischen Access
verwendet. Gewinnung des Bildes geschieht von einer Entfernung von cirka 18
Zentimeter, wobei der Nutzer
aufgefordert wird seine Augen in eine Linie des Lichtstrahls oder
Hologramms zu positionieren. Sobald es korrekterweise der Fall ist, erzeugt das
System die Abbildung des Auges.
Diese Methode bereitet
allerdings auch Probleme für die Nutzer, die Schwierigkeiten damit haben, ihre
Augen genau in dem Strahl zu positionieren, also die, die Orientierungsschwäche
aufweisen.
Abb. PC/Network Access System

6.3 Produkte
Unter den Produkten finden sich
von Desktop-Systemen zur Zugangsberechtigung für PCs über Bankautomaten mit
Iriserkennung, Gebäudezutrittssystemen bis hin zu Kontroll-Systemen auf
Flughäfen für eine Vielzahl von Anwendungsgebieten passende Geräte.[2]
Viele großen und mächtigen Firmen weltweit forschen und produzieren auf diesem Gebiet z.B. Britisch Telecom (UK), NCR Corp (UK), Sensar/Sarnoff Inc. (USA), GTE Corp (USA), Electronic Data Systems (USA), Spring Technologies (USA), Oki Electric Co. (Japan), LG Electronics (Korea), Garny AG (Germany) in unterschiedlichsten Richtungen, wie Telekommunikation, Internetsicherheit, Atomkraftwerksicherheit, Sicherheit von Computerlogins, Electronic Commerce Security, Häftlingskontrollen, Gebäudezutrittssystem, Bankautomaten mit Iriserkennung und weitere. [4]
Der größte Einsatz eines Iriserkennungssystem, den
man heute weltweit beobachten kann, geschieht in den Vereinigten Arabischen
Emiraten, wo alle einreisende Passagiere auf allen 17 Flug-/, See-/ und Landhäfen sich einem
Iriserkennungstest unterziehen sollen. Diese Systeme wurden von IrisGuard Inc. (UK) [http://www.irisguard.com/] installiert und werden von
Ihrem Personal weiter betreut.
Jeden Tag werden ca. 6.500 ankommende Passagiere
einem Iriserkennungstest unterzogen. Dabei wird jede Iris mit den 355.000
Einträgen aus einer „Schwarzen Liste“ verglichen, was sich auf 2.3 Milliarden
Vergleiche pro Tag beläuft. Bisher wurden insgesamt etwa 140 Milliarden
Vergleiche durchgeführt und, laut Angaben vom Inneren Ministerium der
Vereinigten Arabischen Emiraten, ist darunter kein einziger umstritten. [7]
Abb. Einsatz von Iriserken-nungssystemen in den
Vereinigten Arabischen Emiraten

Pilotprojekte, wie das Eye-Scanning wurden in der
Vergangenheit zum Beispiel an Flughäfen in Frankfurt/Main und in Charlotte
(North Carolina) durchgeführt. Dabei unterstützte die Technologie der Firma
EyeTicket aus Virginia (USA) [http://www.eyeticket.com]
die Identifizierung des Flughafenpersonals und der Besatzungscrew.
In der folgenden Tabelle, die auch in dieser Form
auf der Homepage von John Daugman zu finden ist [7],
sind ausgewählte Flughäfen weltweit aufgelistet, in denen die Iriserkennung für
unterschiedliche Zwecke benutzt wird.
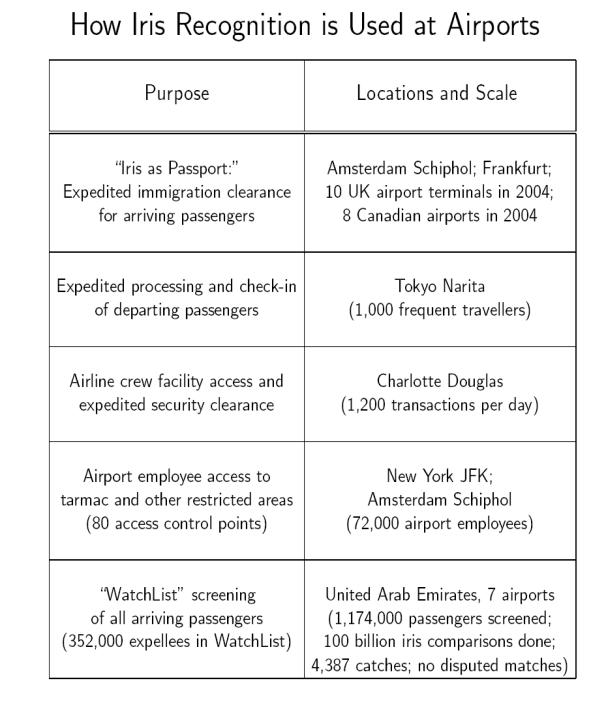
7. Performance der Systeme
Für den
Einsatz eines Iriserkennungssystems spricht nicht zuletzt die Geschwindigkeit
der Bearbeitung, die der Algorithmus und die Bearbeitung des Bildes brauchen.
In der folgenden Tabelle[5] sind die einzelnen Zeiten eines
Iriserkennungsvorganges dargestellt:
|
Operation |
Time |
|
Assess image focus |
15 ms. |
|
Scrub specular reflection |
56 ms. |
|
Localize eye and iris |
90 ms. |
|
Fir pupillare boundary |
12 ms. |
|
Detect and fir both eyelids |
93 ms. |
|
Remove lashes and contact lens edges |
78 ms. |
|
Demodulation and iriscode creation |
102 ms. |
|
XOR comparision of two iriscodes |
10 ms. |
Hier sind die Zeiten der
einzelner Vorgänge bei der Iriserkennung aufgelistet, die sich auf eine 300
MHz. SUN-Workstation beziehen. Außerdem ist zu erwähnen, das das Matching
zweier Iriscodes sehr schnell durchführbar ist, weil XOR Operation (siehe Kap.
„Vergleich mittels HD“) auf der Hardwareebene implementiert und schnell von der
Hardware durchführbar ist. Somit ist eine Matchingengine fähig 100.000
Vergleiche pro Sekunde durchzuführen. Wenn sich eine Datenbank auf deutlich
mehr als 100.000 Einträge ausdehnt, so ist es möglich und sinnvoll den gesamten
Datensatz in 100.000-Sätze Teile zu teilen und parallel zu durchlaufen.
8.
Täuschungsmöglichkeiten:
Die
Sicherheit der Iriserkennungssysteme und die Möglichkeit ein solches System zu
täuschen hängen hauptsächlich davon ab, wie viel Geld man in das System
investiert und welche Sicherheitsanforderungen man an dieses stellt.
Einfachste
Systeme lassen sich bereits durch ein normales Foto einer Iris überlisten.
Im
Netz findet man sogar eine Art Anleitung, wie man Anhand eines Fotos ein
Iriserkennungssystem austricksen kann. Mann schneide einfach ein kleines Loch in das Papier (es soll verhindern,
dass bei Überbelichtung der Aufnahme und Reflexionen eines Fotobildes, falls
man Fotopapier benutzt, ein helles Fleck in der Mitte der Pupille zu sehen
ist), mit der Bildaufnahme der Pupille und nehme das Bild vor dem Auge, so dass
der Iris-Scanner die Bildaufnahme der Iris und die ORIGINALE Pupille (welche
durch das Loch schaut) „sieht“. Damit habe man Zugriff zum System. Die
Bildaufnahme soll eine Auflösung von 2400*1200 dpi haben. Allerdings ist diese
Methode auf den heutzutage gängigen
Iriserkennungssystemen nicht erfolgreich durchführbar, denn eine Routine zur
Lebenderkennung, die z.B. mehrere Beleuchtungen des Auges beim Scannern
hintereinander durchführt und somit das Ausdehnen und Zusammengehen der Pupille
registriert, schon in der Lage ist, diesen Täuschungsversuch aufzudecken.
Außerdem können die Iriserkennungssysteme in der Lage sein, schnellen, nicht
beeinflussbaren Augenbewegungen zu erkennen, was bei einer Bildaufnahme nicht
gegeben ist.
Bemalte
Glasaugen oder bedruckte Kontaktlinsen können Systeme ohne Lebenderkennung
überlisten. Auch
bei einem solchen Täuschungsversuch wäre die Reaktion der Pupille auf das
umgebende Licht nur begrenzt erkennbar. Außerdem lassen sich die Bedruckte
Kontaktlinsen durch ihr charakteristisches Fourierspektrum, d.h. durch die
zweidimensionale Frequenzanalyse des Kamerabildes, erkennen (siehe Abb.)[2].
Abb. Originale Iris Abb. falsche Iris
(bedruckte Kontaktlinse)
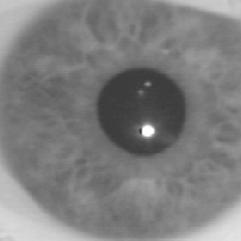
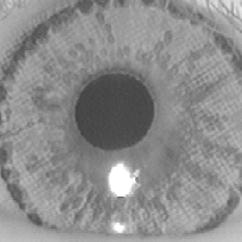
Abb. 2D
Fourierspektrum (originale Iris) Abb. 2D
Fourierspektrum (falsche Iris)


Augenoperationen,
wie in manchen Filmen gezeigt, sind kaum möglich, da die Irismuster zu fein
sind und es eher zu Schädigungen des Auges führt.[1]
Und
mit den Augen eines Toten kann man das System ebenfalls nicht täuschen, da
diese sehr trüb werden und sich die Pupille auf über 80% des normalen
Irisbereichs ausdehnt.[1]
9. Vorteile und Nachteile
9.1 Vorteile
1.
sehr hohe
Erkennungsgenauigkeit, insbesondere stabil gegen eine falsche Übereinstimmung
2.
sehr stabiles
Verfahren
3.
berührungsfreie
Benutzung
4.
geeignet für den
physischen und für den logischen Zugriff
5.
relativ geringer
Speicherbedarf
9.2 Nachteile
1.
mögliche falsche Nichtübereinstimmung
2.
Möglichkeit
für Datenmissbrauch (da die Iris viel mehr Informationen enthält, als man zu
einer Identifikation braucht, z.B. über mögliche Erkrankungen (psychische und
physische) oder Suchtprobleme (Alkoholismus, Drogensucht)
3.
Mangelhafte
Akzeptanz von Menschen für die Verfahren, die sich mit Augen beschäftigen,
wegen psychischer Diskomforts
4.
Verfahren
ist für die Blinden nicht geeignet
5.
Schwierigkeiten
für Nutzer bei der Bedienung
6.
Der
Algorithmus von Daugman wurde patentiert, dies macht das Verbreiten der
Technologie nicht besonderes leicht
10. Vergleichstabellen von biometrischen Verfahren
10.1 Bewertung der biometrischen Verfahren in bezug auf generelle
biometrische Anforderungen
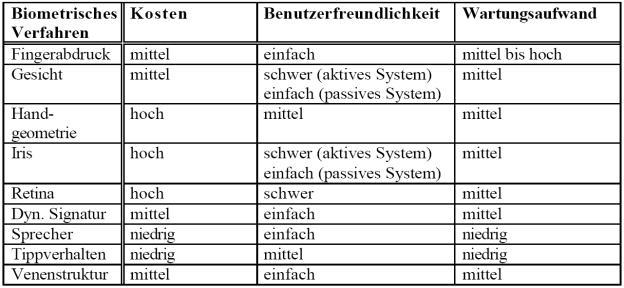
10.2 Bewertung der biometrischen Verfahren in bezug auf Kosten,
Benutzerfreundlichkeit und Wartungsaufwand
10.3 Bewertung der biometrischen Verfahren in bezug auf Anwendungsumgebungen
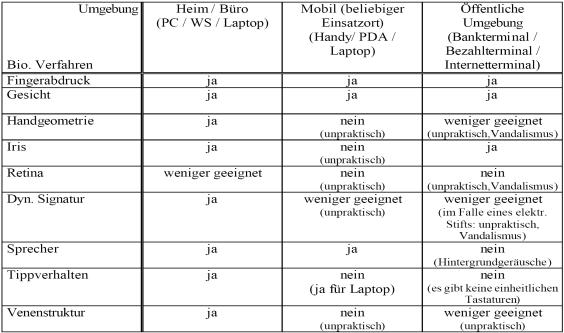 |
11. Literatur
[1] Oliver
Roos, Der Körper als Passwort - Hauptseminar Biometrische Systeme, WS 2003/2004
www.informatik.uni-ulm.de/ni/Lehre/WS03/
HSBiometrie/ausarbeitungen/Roos.pdf
[2] Stefan Schenke, Seminararbeit,
[3] S. Nanavati, M. Thieme, R. Nanavati,
"Biometrics - Identity Verification in a Networked World", A Wiley
Tech Brief, John Wiley & Sons, Inc, 2002
[4] D.D. Zhang, "Automated Biometrics -
Technologies and Systems", Kluwer Academic Publishers, 2000
[5] Anastasia Galkin, Referat,
TU-Berlin,
http://ni.cs.tu-berlin.de/lehre/sem-biometrie/Galkin_Iris.pdf
[6] John Daugman: “How Iris Recognition Works”
http://www.cl.cam.ac.uk/users/jgd1000/irisrecog.pdf
[7] John Daugman’s Homepage, Institute of Mathematics and Informatics, University of
Groningen
http://www.cl.cam.ac.uk/users/jgd1000
[8] Martin
Johns, Diplomarbeit:
„Anwendung
von Wavelets für die Biometrische Authentikation“
http://www.polyboy.net/akademisches/diplomarbeit/html/
[9] www.biometrie.de
[10] www.iridiantech.com
[11] John
Daugman: „Iris Recognition“ American Scientist, Volume 89
http://www.securimetrics.com/articles/gfx/Iris_PDF_file.pdf
ausgearbeitet von:
Elena Filatova: filatova@informatik.hu-berlin.de
Roman Keller: rkeller@informatik.hu-berlin.de